Conteúdo duplicado ocorre quando duas URLs compartilham o mesmo texto ou parte dele, sendo algo altamente prejudicial para SEO.
Observe no exemplo abaixo o texto de uma página de produto de um grande marketplace.

Pegando o trecho em destaque e presuisando-o entre aspas no Google (para retornar correspond&ências exatas), observamos os eventos abaixo.
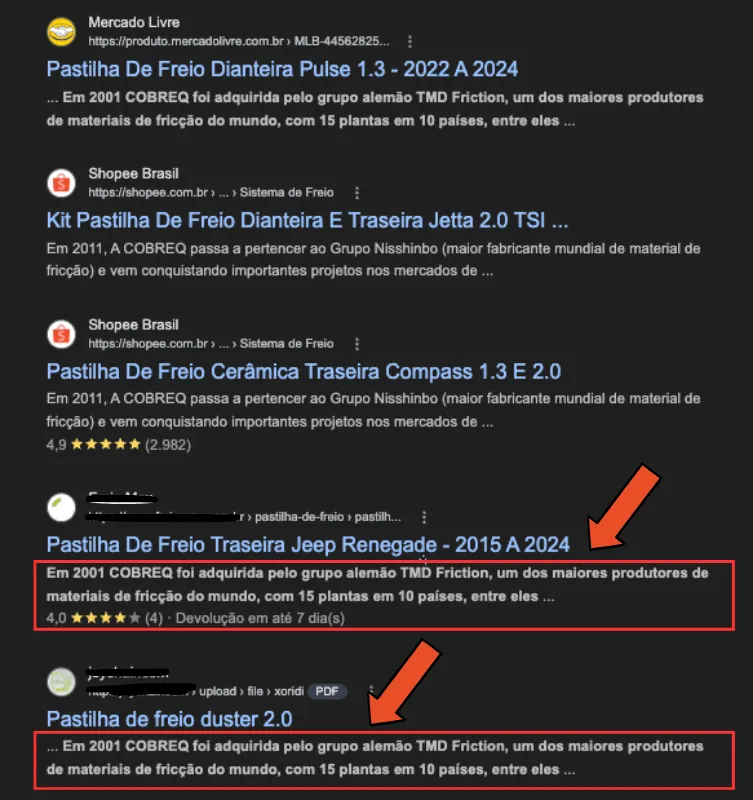
Dá para ver que conteúdo duplicado é mais comum do que parece.
Mas, nem toda ocorrência é um sinal ruim ou algo difícil de resolver.
Neste guia completo, você entenderá como identificar as causas invisíveis da duplicidade, desde falhas técnicas até o impacto nas buscas pela IA.
Além disso, vamos falar sobre um experimento feito em um dos nosso projetos e os efeitos percebidos.
Por que o Conteúdo Duplicado é a “Queda Silenciosa” do Tráfego Orgânico?
Manter um posicionamento de destaque no Google exige mais do que apenas volume de postagens; exige integridade técnica e relevância estratégica.
O conteúdo duplicado é um dos maiores obstáculos para o crescimento orgânico, atuando como uma “âncora” que impede páginas de alta qualidade de performarem.
Com a evolução dos algoritmos e a chegada das buscas por IA, a originalidade deixou de ser opcional para se tornar o pilar central da autoridade digital.
Muitos gestores acreditam que o Google aplica punições manuais imediatas para textos repetidos, mas o dano costuma ser mais sutil e técnico.
Quando o buscador encontra várias versões de um mesmo conteúdo, ele enfrenta um dilema: qual delas deve ser indexada e rankeada?
O resultado é a diluição da força da sua página e a confusão dos algoritmos.
O impacto do Conteúdo Duplicado na Autoridade do Site e no E-E-A-T
A qualidade de um site hoje é medida pelo E-E-A-T (Experiência, Especialidade, Autoridade e Confiança).
Conteúdos repetidos ou “clonados” sinalizam ao algoritmo que o site não possui expertise original ou valor real para o usuário.
Se o seu conteúdo não traz uma perspectiva única, ele falha em demonstrar a autoridade necessária para ocupar as primeiras posições.
Dado Relevante: Estudos indicam que até 29% da web é composta por conteúdo duplicado.
No entanto, sites que sofrem com canibalização de palavras-chave devido à duplicidade podem ver uma queda de até 40% na eficiência do rastreio de novas páginas.
Como as Visões de IA do Google (AI Overview e AI Mode) filtram repetições
O Google utiliza inteligência artificial para sintetizar respostas diretas.
A IA do Google é treinada para filtrar redundâncias e priorizar fontes que ofereçam informações incrementais.
Sites com alta taxa de duplicidade são sumariamente ignorados pelos resumos de IA, pois não contribuem com novos dados ou contextos para a resposta gerada.
Causas Comuns de Duplicidade de Conteúdo
A duplicidade raramente nasce da má-fé; na maioria das vezes, ela é fruto de erros estruturais na configuração do site.
-
Variações de URL: Quando a mesma página pode ser acessada por diferentes versões de endereço (com ou sem “www”, http e https, com barra no final ou com parâmetros), os buscadores podem entender que são páginas distintas com o mesmo conteúdo.
-
Parâmetros e filtros de navegação: Em e-commerces, filtros por cor, tamanho, preço ou ordenação criam novas URLs que exibem praticamente o mesmo conteúdo, gerando múltiplas versões de uma mesma página.
-
Paginação de conteúdo: Listagens de produtos ou artigos divididas em várias páginas (page=1, page=2, etc.) podem causar similaridade excessiva entre as URLs.
-
Descrições de produtos copiadas: Utilizar textos fornecidos por fabricantes, sem personalização, faz com que vários sites publiquem exatamente o mesmo conteúdo.
-
Categorias, tags e arquivos automáticos: Plataformas como WordPress criam páginas de categoria, tag, autor e data que replicam trechos dos artigos, aumentando o risco de duplicação interna.
-
Versões para impressão ou AMP: Criar versões alternativas da mesma página (como /print ou AMP) sem indicar qual é a principal pode gerar conflito de indexação.
-
Conteúdo republicado em outros sites: Publicar o mesmo artigo em múltiplos domínios, sem usar a tag canonical correta, pode dividir autoridade e prejudicar o ranqueamento.
Conteúdo Duplicado no E-commerce: Variações e Filtros
Para lojas virtuais, o conteúdo duplicado é um desafio técnico diário que afeta diretamente o Crawl Budget (orçamento de rastreio).
Descrições de Fornecedores
Muitos e-commerces utilizam as descrições padrão enviadas pelos fabricantes.
O problema? Centenas de concorrentes fazem o mesmo. Para o Google, não há motivo para rankear a sua página se ela é uma cópia exata de grandes players do mercado.
Personalizar as descrições é fundamental para injetar Experiência e Especialidade no seu catálogo.
Faceted Navigations
A navegação por facetas (filtros de cor, tamanho, marca) é essencial para a UX, mas pode ser um pesadelo para o SEO.
Cada combinação de filtro gera uma nova URL. Se não houver uma gestão correta, o Google desperdiçará recursos rastreando milhares de páginas irrelevantes, deixando de indexar o que realmente importa: seus produtos principais.
Como Diagnosticar e Resolver a Duplicidade de Conteúdo
Resolver a duplicidade exige uma abordagem estratégica que combine limpeza de código e unificação de valor.
Use Canonical Tags e Meta Robots (noindex)
A Canonical Tag (rel=”canonical”) é a forma de dizer ao Google: “Eu sei que existem outras versões desta página, mas esta é a oficial”.
Já o Meta Robots “noindex” deve ser usado em páginas que são úteis para o usuário (como termos de uso ou filtros específicos), mas que não possuem valor de busca.
Faça Unificação de Conteúdo
Se você tem três artigos curtos e semelhantes sobre o mesmo tema (o que chamamos de Thin Content), a melhor solução não é deletar, mas sim fundi-los em um Guia Definitivo.
Isso concentra a autoridade dos links e transforma conteúdos rasos em um material robusto e profundo.
| Método | Quando Usar | Objetivo Principal |
| Redirecionamento 301 | URLs antigas ou páginas duplicadas permanentemente. | Transferir 100% da autoridade para a nova URL. |
| Canonical Tag | Páginas com variações de parâmetros (filtros de e-commerce). | Consolidar sinais de rankeamento em uma URL “mestre”. |
| Meta Noindex | Páginas administrativas, carrinhos ou resultados de busca interna. | Impedir que o Google perca tempo indexando lixo técnico. |
Crie Conteúdo que o Google não consegue ignorar
Na era da IA, a otimização vai além da repetição de palavras-chave. O foco agora é a cobertura tópica e o contexto semântico.
Um artigo de alta qualidade deve responder não apenas à pergunta principal, mas também às dúvidas latentes do usuário.
O Google valoriza o que chamamos de “Ganho de Informação” (Information Gain). Se o seu artigo apenas repete o que os 10 primeiros resultados dizem, ele é, para fins algorítmicos, um conteúdo duplicado em conceito.
Para se destacar, utilize dados reais, cite estudos de caso e crie comparações que ferramentas de automação simples não conseguem replicar.
Ferramentas Essenciais para Diagnóstico
Para manter a saúde do seu site, é necessário utilizar ferramentas que identifiquem a duplicidade antes que o Google o faça:
- Screaming Frog: Essencial para identificar títulos e H1s duplicados em larga escala.
- Siteliner: Focada especificamente em encontrar conteúdo idêntico dentro do seu próprio domínio.
- Copyscape: A ferramenta padrão para verificar se o seu conteúdo foi plagiado por terceiros na web.
- Google Search Console: Verifique a seção de “Páginas” para encontrar URLs rastreadas, mas não indexadas devido à duplicidade.
O Impacto do Conteúdo Duplicado na Experiência do Usuário
A duplicidade não afeta apenas robôs; ela destrói a Experiência do Usuário (UX).
Encontrar a mesma informação repetida em páginas diferentes do mesmo site gera frustração e diminui a percepção de profissionalismo da marca.
- Aumento da Taxa de Rejeição: O usuário sente que está em um “loop” de informações.
- Perda de Confiança: Se a empresa não cuida da própria organização, o usuário questiona a qualidade do serviço.
- Dificuldade de Conversão: O excesso de páginas similares confunde a jornada de compra.
Estratégias Avançadas de Prevenção
- Padronização de Links Internos: Sempre linke para a versão canônica da URL (evite misturar links com e sem barra no final, ou maiúsculas/minúsculas).
- Gestão de Syndication: Se você distribui seu conteúdo para outros portais, exija o uso da tag rel=”canonical” apontando para o seu site original.
- Auditorias Periódicas: Sites dinâmicos mudam constantemente. Uma auditoria trimestral é o mínimo para garantir que novos parâmetros de URL não estejam criando duplicidade “fantasma”.
O Experimento da “Canibalização Controlada”
Em um experimento realizado com um e-commerce de médio porte, a unificação de 15 páginas de produtos similares em apenas uma “Página Pilar” resultou em um aumento de 65% no tráfego orgânico para aquele termo em apenas 60 dias.
Isso ocorre porque, ao eliminar a duplicidade, o Google para de dividir o PageRank entre várias URLs e foca toda a relevância em um único ponto.
Conclusão
O conteúdo duplicado não deve ser visto apenas como um erro, mas como uma oportunidade de organizar a arquitetura do seu site para o sucesso de longo prazo.
Ao resolver esses conflitos, você libera o caminho para que o Google entenda exatamente qual valor sua marca entrega ao mercado.
Proteger o seu tráfego orgânico exige vigilância constante e uma estratégia de conteúdo que priorize a experiência humana acima de qualquer atalho técnico.
A clareza técnica aliada à profundidade editorial é a única fórmula garantida para rankear com consistência na era da inteligência artificial.
Perguntas Frequentes (FAQ)
1- Conteúdo duplicado gera punição do Google?
Não existe uma “punição” oficial no sentido de banimento, a menos que seja um plágio massivo e malicioso.
O que ocorre é uma perda drástica de visibilidade, pois o Google filtra o que considera redundante.
2- Qual a diferença entre Canonical Tag e Redirecionamento 301?
O redirecionamento 301 é uma ordem física: ele leva o usuário e o robô de uma URL A para uma URL B.
A Canonical Tag é uma sugestão de indexação: as duas URLs permanecem acessíveis, mas o Google concentra a autoridade em uma delas.
3- O Google entende traduções como conteúdo duplicado?
Não. Conteúdo traduzido manualmente para outros idiomas é considerado conteúdo único.
No entanto, traduções automáticas de baixa qualidade sem revisão podem cair na categoria de “conteúdo gerado por spam”.
4- Como lidar com descrições de produtos muito parecidos?
Foque nas diferenças. Se você vende uma camiseta em 10 cores, não crie 10 páginas com o mesmo texto mudando apenas a cor.
Use uma página única com seletores de cor ou garanta que cada página tenha insights específicos sobre o uso daquela cor/modelo.
Precisa de ajuda para auditar seu site e eliminar erros críticos de SEO?
A DGAZ Marketing é especialista em estratégias de Growth e SEO e Mídia Paga para empresas que buscam crescimento sustentável.
Fale com nossos especialistas e solicite um diagnóstico agora!